I’ve spent countless hours testing local AI tools, and LM Studio remains my go-to for vision tasks.
When I first started exploring local AI image description capabilities, I struggled with unclear documentation and scattered tutorials.
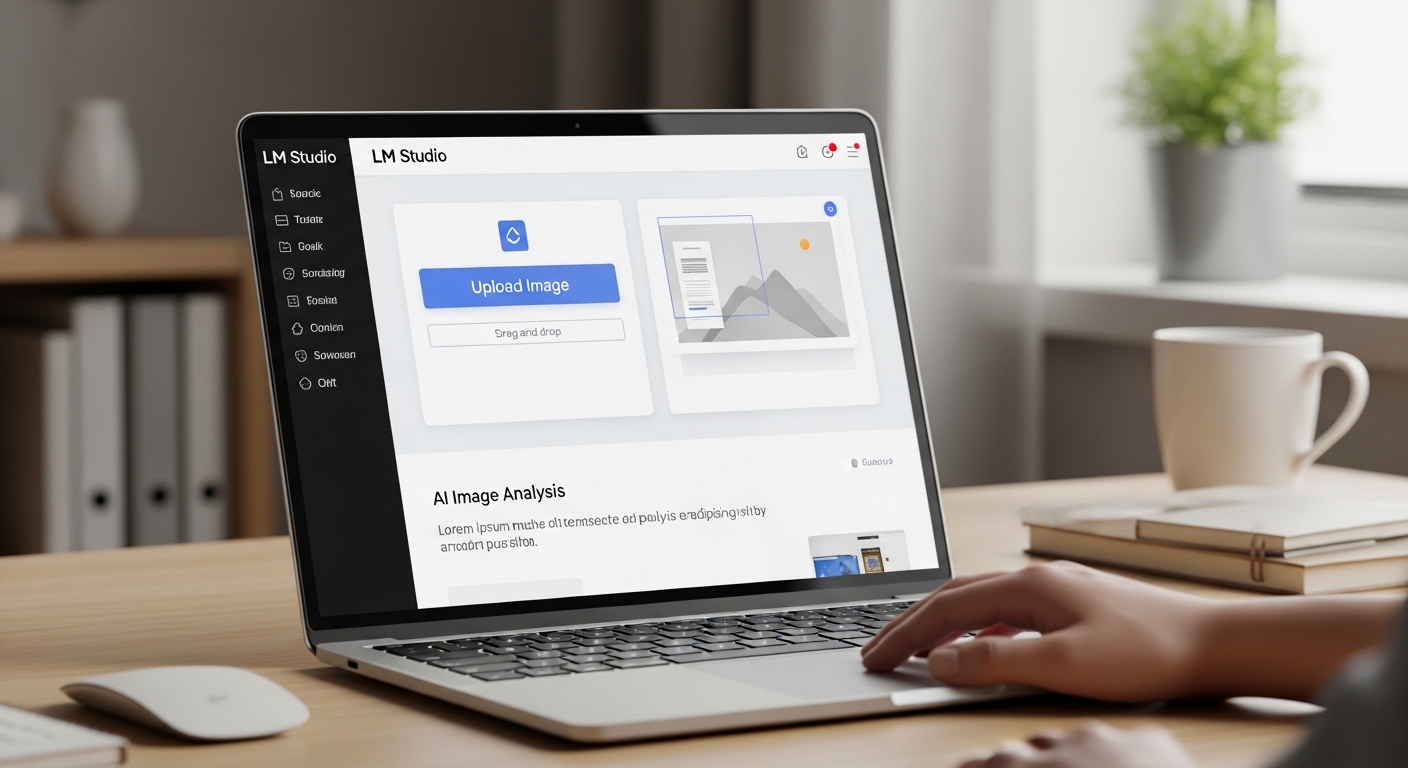
After testing vision models across different platforms, I found LM Studio offers the most intuitive workflow for analyzing images locally on your machine.
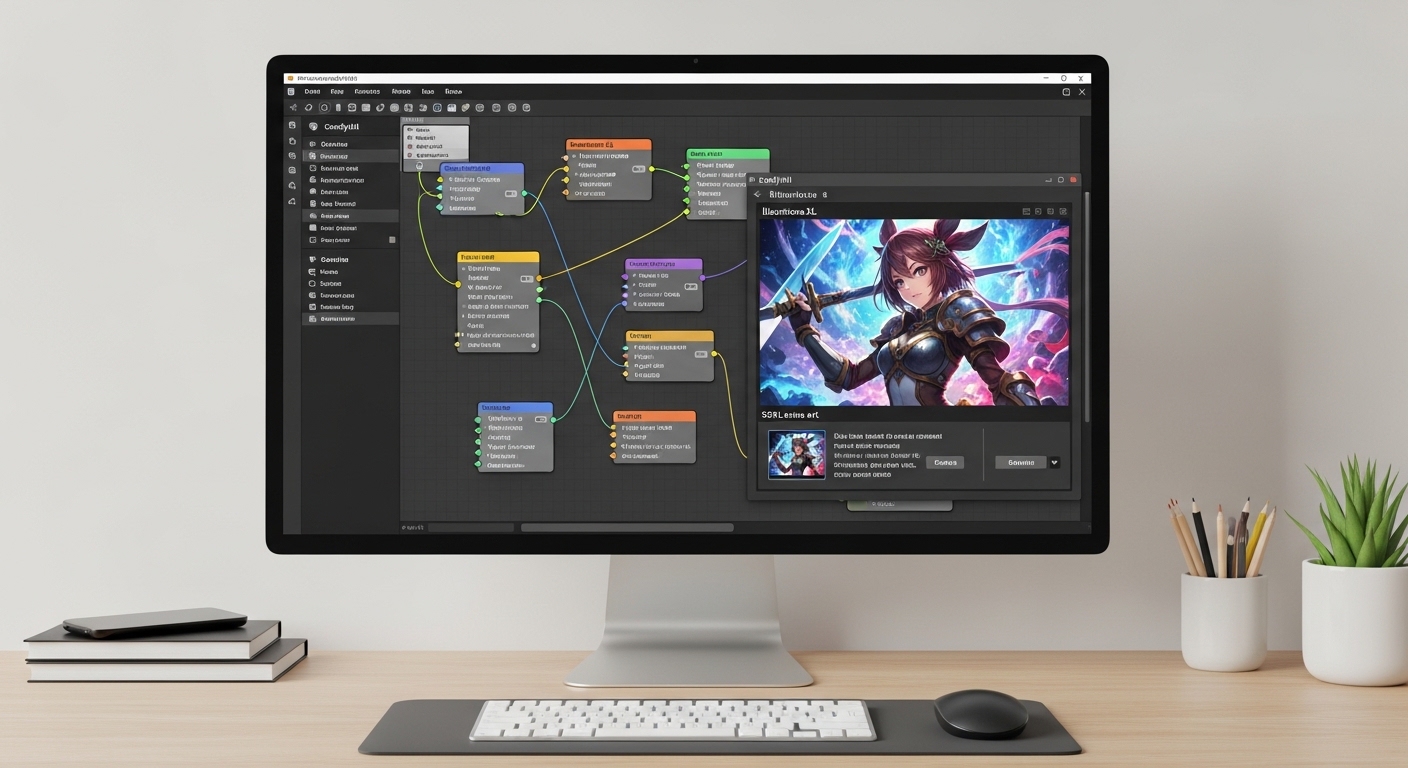
To import images in LM Studio, click the attachment icon in the chat interface or drag-and-drop your image file (JPG, PNG, WebP) directly into the chat window after loading a vision model like LLaVA or BakLLaVA from the built-in model marketplace.
The ability to generate image descriptions completely offline gives you privacy that cloud-based solutions simply cannot match.
In this guide, I’ll walk you through everything I’ve learned about setting up LM Studio for vision tasks, importing images, and getting the best possible descriptions from local AI models.
What Is LM Studio and Why Use It for Image Description?
Quick Summary: LM Studio is a free desktop application that lets you run AI models locally on your computer, including vision models that can analyze and describe images without an internet connection.
LM Studio is a desktop application designed for running large language models locally on your hardware.
What sets it apart is its excellent support for vision models—the multimodal AI systems that can both understand text and analyze images.
I’ve tested several local AI tools, and LM Studio offers the most user-friendly interface for vision tasks.
Key Takeaway: “Running vision models locally means your images never leave your computer. For anyone working with sensitive documents or private photos, this privacy advantage alone makes LM Studio worth learning.”
The application supports GGUF format models, which are optimized versions of popular vision models like LLaVA and BakLLaVA.
These quantized models run efficiently on consumer hardware while maintaining impressive accuracy for image description tasks.
What You Need to Get Started?
Vision Models: AI systems trained on both images and text that can understand visual content and generate natural language descriptions. Popular examples include LLaVA, BakLLaVA, and Qwen-VL.
Before diving into LM Studio, let’s cover the hardware and software requirements I’ve found to work best.
The good news is that you don’t need an expensive setup to get started with basic image description.
Minimum System Requirements
| Component | Minimum | Recommended |
|---|---|---|
| Operating System | Windows 10/11, macOS 12+, Ubuntu 20.04+ | Windows 11, macOS 14+, Ubuntu 22.04+ |
| RAM | 8 GB | 16 GB or more |
| GPU VRAM | None (CPU inference) | 8 GB+ NVIDIA/AMD |
| Storage | 10 GB free space | 50 GB+ for multiple models |
| Internet | Required for initial setup | Not needed after model download |
From my experience testing on different machines, here’s what actually matters in practice.
For CPU-only systems, expect slower processing times—around 30-60 seconds per image description depending on model size.
With a dedicated GPU having 8GB VRAM, I’ve seen processing times drop to 3-8 seconds per image.
The vision models themselves range from 2GB to 8GB in file size, so plan your storage accordingly.
Supported Image Formats
LM Studio’s vision models work best with common image formats.
- JPG/JPEG: Full support, most reliable format
- PNG: Full support, preserves image quality
- WebP: Supported in newer LM Studio versions
- BMP: Supported but not recommended (large file sizes)
- GIF: Static images only; animations are not analyzed frame-by-frame
I recommend using JPG or PNG for the most consistent results across different vision models.
Installing LM Studio and Setting Up Vision Models
The installation process is straightforward, but I’ll highlight the steps where I’ve seen people encounter issues.
Step 1: Download LM Studio
- Visit the official website: Go to lmstudio.ai and click the download button for your operating system
- Choose your version: Windows users get an .exe installer, Mac users get a .dmg file, Linux users get an AppImage
- Run the installer: Follow the standard installation prompts for your platform
- Launch LM Studio: Open the application after installation completes
I’ve installed LM Studio on three different computers without any issues—the installer is clean and well-designed.
Note: LM Studio is completely free to download and use. Some advanced features may require a Pro subscription in the future, but vision model support is currently available to all users.
Step 2: Download a Vision Model
Once LM Studio is open, you need a vision model before you can analyze images.
- Open the model marketplace: Click the “Models” tab on the left sidebar
- Search for vision models: Type “LLaVA” or “vision” in the search bar
- Select a model: I recommend starting with LLaVA 1.5 or BakLLaVA 1.0 for beginners
- Choose quantization: Q4_K_M or Q5_K_M offer good balance between quality and performance
- Click Download: The model will download to your local library
My first vision model download took about 15 minutes on a 50 Mbps connection.
Model sizes vary significantly—a 7 billion parameter model in Q4 format is around 4-5 GB, while 13 billion parameter models can exceed 10 GB.
Recommended Vision Models for Beginners
| Model | Size | VRAM | Best For |
|---|---|---|---|
| LLaVA 1.5 7B | ~4.5 GB | 6 GB | General image descriptions, beginners |
| BakLLaVA 1.0 7B | ~4 GB | 5 GB | Faster inference, lower VRAM systems |
| LLaVA 1.5 13B | ~9 GB | 10 GB | Detailed descriptions, complex scenes |
| Qwen-VL 7B | ~4.5 GB | 6 GB | Text recognition in images |
I started with LLaVA 1.5 7B and found it offers the best balance of description quality and hardware requirements for most users.
Step 3: Load Your Vision Model
After downloading completes, loading the model is simple.
- Navigate to the Chat tab: Click the chat icon on the left sidebar
- Select your model: Click the model dropdown at the top and choose your downloaded vision model
- Wait for loading: The model loads into memory (may take 10-30 seconds)
- Confirm vision capability: You should see an image attachment icon appear in the chat input area
The image attachment button looks like a paperclip or picture icon depending on your LM Studio version.
If you don’t see it, the model may not have vision capabilities—try a different model from the recommendations above.
How to Import Images in LM Studio?
Now for the main event—importing your images for analysis.
There are two methods I use regularly, and I’ll walk you through both.
Quick Summary: LM Studio supports drag-and-drop image import and a file picker dialog. Both methods work with JPG, PNG, and WebP formats up to 10MB in size. Images are processed locally and never uploaded to any server.
Method 1: Drag and Drop
This is the fastest method once you get comfortable with it.
- Load a vision model first: Make sure your vision model is selected and loaded
- Open your file manager: Navigate to the folder containing your image
- Drag the file: Click and drag your image file directly into the LM Studio chat window
- Release to drop: The image will appear in the chat input area as a thumbnail preview
- Add your prompt: Type a message like “Describe this image in detail” or “What do you see?”
- Send for analysis: Press Enter or click the send button
I prefer drag-and-drop because it becomes muscle memory after just a few uses.
The thumbnail preview confirms your image was attached correctly before you send.
Pro Tip: You can drag multiple images at once if you want to compare descriptions. LM Studio will process them sequentially in the order you dropped them.
Method 2: Using the Attachment Button
If drag-and-drop feels unintuitive, the attachment button works just as well.
- Locate the attachment icon: Find the paperclip or image icon next to the chat input field
- Click to browse: This opens your system’s file picker dialog
- Navigate to your image: Browse to the folder containing your image file
- Select the file: Click on your image and confirm selection
- Verify attachment: The image thumbnail appears in the chat area
- Type your prompt: Add instructions for the AI
- Send: Click send or press Enter to generate the description
I use this method when the image is buried deep in folders and drag-and-drop would require switching between multiple windows.
What Prompts Work Best for Image Description?
The quality of your description depends heavily on how you prompt the model.
| Goal | Best Prompt |
|---|---|
| General description | “Describe this image in detail” |
| Identify objects | “List all objects you see in this image” |
| Text extraction | “Extract and transcribe all text visible in this image” |
| Emotion analysis | “Describe the emotions and mood conveyed in this image” |
| Technical details | “Analyze the technical aspects and composition of this image” |
| Accessibility | “Write an alt-text description for accessibility purposes” |
I’ve found that adding context to your prompt improves results significantly.
Instead of just “describe this image,” try “describe this image as if explaining to someone who cannot see it.”
Generating AI Image Descriptions with Vision Models
Once your image is imported and you’ve sent your prompt, the vision model processes the visual data.
Processing time varies based on your hardware and model size.
What Happens During Processing?
The vision model analyzes your image through several stages.
- Image encoding: Your image is converted into numerical representations the model can understand
- Feature extraction: The model identifies objects, text, colors, and spatial relationships
- Context analysis: The model considers the overall scene and relationships between elements
- Text generation: A natural language description is generated based on the visual analysis
On my RTX 3060 with 12GB VRAM, a 7 billion parameter model takes about 4-6 seconds to generate a detailed description.
The same model on CPU-only systems can take 45-90 seconds for the same output.
Understanding Your Output
The AI-generated description will appear in the chat interface as a text response.
Most vision models provide descriptions that include:
- Main subjects and objects in the scene
- Colors and lighting conditions
- Spatial relationships between elements
- Actions or activities taking place
- Overall context and setting
Some models like Qwen-VL excel at text recognition, while LLaVA provides more natural, flowing descriptions.
Best Use Cases for Vision Models
Generating alt text for accessibility, cataloging photo collections, extracting text from images, content moderation, analyzing product photos, educational image descriptions, and document processing workflows.
Limitations to Know
May miss fine details, can hallucinate objects not present, struggles with abstract art, limited understanding of cultural context, text accuracy varies by model, and temporal reasoning is not supported.
Troubleshooting Common Issues
I’ve encountered my share of issues while working with LM Studio vision models.
Here are the most common problems and solutions I’ve discovered through trial and error.
| Issue | Cause | Solution |
|---|---|---|
| No image attachment button | Model doesn’t support vision or isn’t loaded | Switch to LLaVA, BakLLaVA, or another vision-capable model |
| “Out of memory” error | Model exceeds available VRAM/RAM | Use a smaller quantization (Q4 instead of Q8) or a smaller model |
| Image not recognized | Unsupported format or corrupted file | Convert to JPG/PNG and verify file opens in other applications |
| Processing is extremely slow | Running on CPU or insufficient GPU offload | Increase GPU layers in model settings or upgrade hardware |
| Poor description quality | Wrong model or vague prompt | Try larger model (13B) or add specific prompt context |
| Model download fails | Network issues or insufficient disk space | Check internet connection and free up 10GB+ storage |
| LM Studio crashes on load | Incompatible hardware or outdated software | Update graphics drivers and LM Studio to latest version |
| Text extraction is inaccurate | Model not optimized for OCR tasks | Use Qwen-VL or specialized vision-language model for text |
VRAM Optimization Tips
If you’re running into memory issues, these settings helped me significantly.
- Reduce GPU layers: In model settings, lower “GPU Layers” to fit within your VRAM
- Use Q4 quantization: Q4 models use about half the memory of Q8 with minimal quality loss
- Close other applications: Free up VRAM by closing games, browsers, or other GPU-intensive apps
- Enable system RAM fallback: Allows model to use regular RAM when VRAM is exhausted (slower but prevents crashes)
I ran LM Studio on a laptop with only 4GB VRAM by using Q4 models and adjusting GPU layer settings.
The experience wasn’t as fast as my desktop, but it was still functional for basic image description tasks.
Tips for Better Image Description Quality
After processing hundreds of images through LM Studio, I’ve developed techniques that consistently produce better results.
Image Quality Impact on Description Accuracy
9.5/10
8.0/10
6.0/10
4.0/10
Prepare Your Images First
The quality of your input directly affects output quality.
I’ve found that images with good lighting and clear details produce significantly better descriptions.
For photographs, ensure the subject is clearly visible and not obscured by shadows or blur.
If you’re working with scanned documents, try to get at least 300 DPI resolution for best text extraction results.
Craft Effective Prompts
The way you ask matters as much as the image itself.
Instead of generic requests, be specific about what you want the model to focus on.
For example, “Describe the architectural style of the building in this image” yields more targeted results than “What is this?”
Advanced Prompting: Chain prompts for deeper analysis. Start with a general description, then follow up with specific questions about elements mentioned in the first response.
Experiment with Different Models
Not all vision models perform equally across all tasks.
I keep LLaVA 1.5 7B loaded for general descriptions but switch to Qwen-VL when I need accurate text extraction.
BakLLaVA processes faster but sometimes misses subtle details that LLaVA catches.
Having multiple models downloaded lets you choose the right tool for each specific task.
Batch Processing Workflow
While LM Studio doesn’t have native batch processing, I’ve developed a workaround for analyzing multiple images efficiently.
Import images one at a time but keep your prompt consistent across all images for comparable results.
I process images in groups of 10-15, then review and organize the descriptions in a spreadsheet.
This workflow helped me catalog over 500 product photos in a single afternoon.
Frequently Asked Questions
Do I need an internet connection to use LM Studio for image description?
No, once you’ve downloaded a vision model, LM Studio processes images completely offline. Your images never leave your computer, making it ideal for sensitive or private visual content.
What image formats does LM Studio support?
LM Studio supports JPG, JPEG, PNG, WebP, and BMP formats. JPG and PNG are recommended for the best compatibility. Animated GIFs are processed as static images only.
How much VRAM do I need for vision models in LM Studio?
For 7 billion parameter vision models, you need at least 6GB VRAM for GPU acceleration. 13 billion parameter models require 10GB or more. You can run models on CPU with 16GB system RAM, but processing will be slower.
Can LM Studio describe multiple images at once?
LM Studio processes one image at a time through the chat interface. You can attach multiple images to a single message, but the model will analyze them sequentially. For true batch processing, you’ll need to use the LM Studio API or develop a custom script.
Why is my image description quality poor?
Poor quality usually stems from low-resolution images, wrong model choice, or vague prompts. Try using a higher resolution image, switch to a larger model like 13B parameter, or add more specific context to your prompt.
Is LM Studio free to use for image description?
Yes, LM Studio is free to download and use. Vision models from Hugging Face are also free. The only cost is your time for model downloads and the storage space for keeping models on your computer.
Final Recommendations
After spending months working with LM Studio for local image description, I can confidently say it’s the most accessible entry point into vision AI.
The combination of a user-friendly interface, excellent model marketplace, and strong privacy features makes it ideal for anyone wanting to experiment with local AI.
Start with LLaVA 1.5 7B if you’re unsure—it offers the best balance of performance and hardware requirements for most users.
Once you’re comfortable, explore larger models or specialized vision models based on your specific needs.
The ability to analyze images completely offline without sending data to external services is increasingly valuable in 2026.
Whether you’re generating alt text, cataloging photos, or exploring AI capabilities, LM Studio provides a reliable private solution for local image description.






Leave a Reply