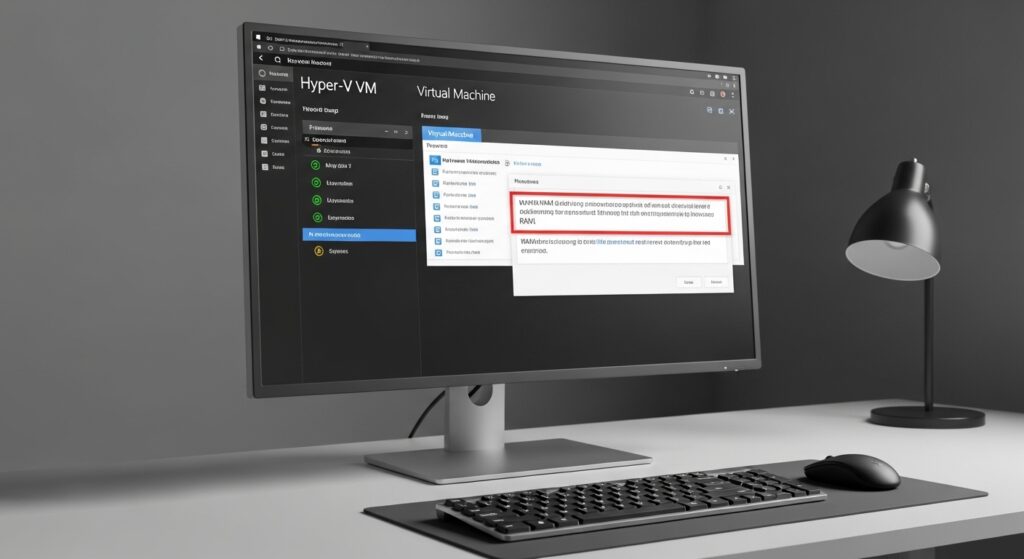
How To Fix The Unable To Allocate RAM Error In Hyper-V VMs
Complete guide to fixing the unable to allocate RAM error in Hyper-V virtual machines. Learn 7 proven solutions from Dynamic Memory configuration to advanced PowerShell troubleshooting.
Complete guide to fixing the unable to allocate RAM error in Hyper-V virtual machines. Learn 7 proven solutions from Dynamic Memory configuration to advanced PowerShell troubleshooting.

Free interactive Valorant Points calculator to convert VP to USD. Complete pricing table for all 8 VP bundles with value analysis and regional pricing comparison.

Complete troubleshooting guide to fix Windows CMD terminal freezing issues. Learn the 7 common causes and 12 proven solutions, from quick fixes to advanced diagnostics.
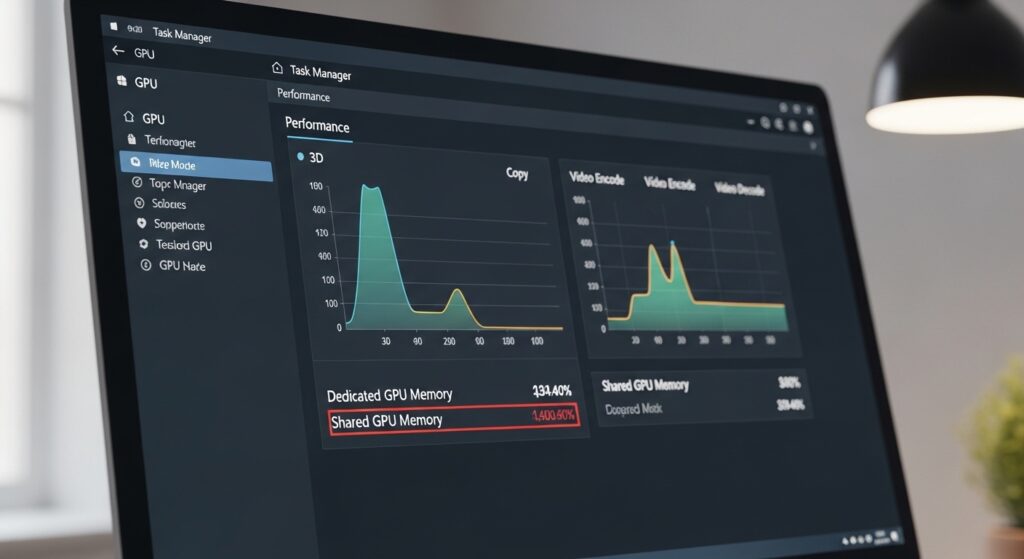
Shared GPU memory is a portion of your system RAM that your graphics processor uses when dedicated video memory is full. Learn how it works and whether it affects performance.
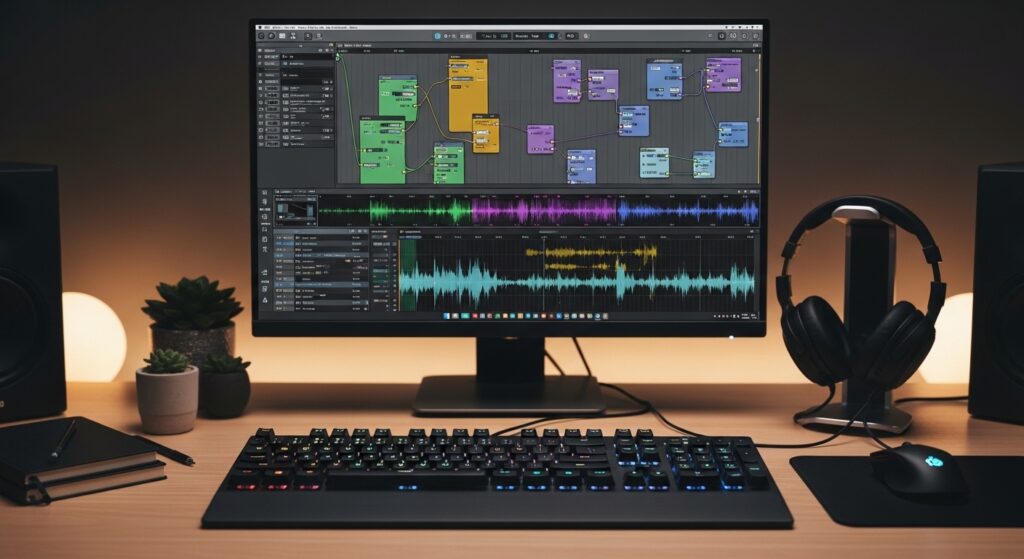
Complete step-by-step tutorial for setting up ACE (Audio Conditioned Encoder) in ComfyUI to generate AI music locally. Learn system requirements, installation process, and workflow creation.
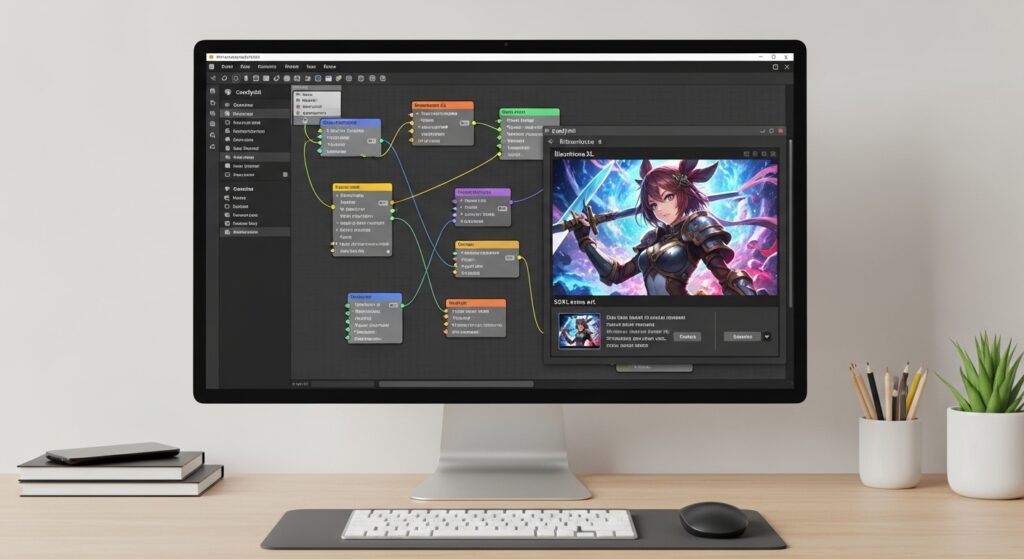
Step-by-step beginner’s guide to generating stunning anime artwork with Illustrious XL SDXL model in ComfyUI. Learn installation, workflow setup, prompts, and troubleshooting.
Running a Minecraft server with the right plugins makes all the difference. After testing hundreds of plugins across 5+ years of server administration, here are the 12 essential vanilla plus Spigot plugins that enhance gameplay without breaking the authentic Minecraft experience.
Complete guide to browsing TikTok without an account or app. Learn how to use TikTok Web, third-party viewers, and privacy tools to watch videos anonymously.
Complete guide to booru style tagging for SDXL anime prompts. Learn the structured tagging system with 15+ copy-paste examples, tag syntax rules, and advanced techniques for consistent anime art generation.
Master Telegram search with proven methods to find quality groups, chats, and channels. Learn built-in search tricks, directory websites, Google operators, and safety tips to avoid spam communities.